概念定义
注意力机制允许 LLM 在生成或解释文本时,权衡序列中不同词元的重要性。它通过计算查询(query)、键(key)和值(value)向量之间的相似度得分(例如使用点积运算),来聚焦于相关的词元。例如,在句子“The cat chased the mouse”(猫追老鼠)中,注意力机制可以帮助模型将“mouse”(老鼠)与“chased”(追)联系起来。这种机制提高了对上下文的理解能力,使得 Transformer 在自然语言处理(NLP)任务中非常高效。
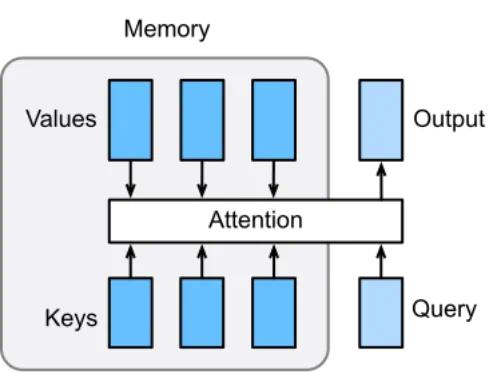
第一性原理剖析:注意力机制的本质
想象一下,你正在阅读一段很长的文字。当你读到某个词语时,你的大脑并不会平等地看待这段文字中的所有其他词语。相反,你会根据当前正在处理的这个词,有选择地、有侧重地关注与之最相关的几个词,以便更好地理解其含义。
例如,读到句子“那只灰色的猫懒洋洋地趴在温暖的壁炉边的垫子上”中的“趴”字时,你的大脑会立刻将注意力高度集中在“猫”上,同时也会关联到“垫子”和“壁炉边”,因为这些词共同构建了“趴”这个动作的场景。而“灰色”或“温暖”这些词,虽然提供了背景信息,但在理解“趴”这个动作本身时,重要性就稍低一些。
这就是“注意力”的本质:一种资源分配机制,它将有限的认知资源(或计算资源)集中在当前任务最关键的信息上。
注意力机制如何运作的
-
第一步:匹配(计算注意力得分) 你拿着你的“查询”(Query - “人工智能经济影响”),去和图书馆里每一本书的“键”(Key - 标签)进行比对。
- 和“科技、经济、21世纪”这个标签一比,发现相关度很高(匹配得分高)。
- 和“历史、艺术、文艺复兴”这个标签一比,发现相关度很低(匹配得分低)。 这个比对过程,在模型里通常就是你提到的“点积运算”。它计算出你的“查询”和每一个“键”之间的相似度得分。
-
第二步:加权(分配注意力权重) 你根据这个相关度得分,来分配你的“注意力”。你会花90%的精力去看那本关于科技和经济的书,可能只会花0.1%的精力(甚至不看)那本关于文艺复兴的书。这个百分比,就是“注意力权重”。得分越高的,权重越大。通常会用一个叫做 Softmax 的函数来将原始的得分转换成总和为1的权重比例。
-
第三步:汇总(得到最终结果) 最后,你根据分配好的注意力权重,去“阅读”那些书的“值”(Value - 实际内容)。你将90%的权重乘以《科技与经济》的内容,加上0.1%的权重乘以《文艺复兴史》的内容…… 最终,你脑海里形成的知识,是一个加权融合后的信息。这个信息高度集中了与你查询最相关的内容,同时又没有完全丢弃其他(可能次要的)信息。
这个最终得到的加权“值”的总和,就是注意力机制的输出。它是一个全新的信息表示,它告诉模型:“对于你当前正在处理的这个词,综合整个句子的信息来看,这是与它最相关的上下文精华。”
graph TD subgraph "输入序列 (Input Sequence)" T(The) C(cat) CH(chased) M(mouse) end subgraph "注意力计算 (当处理 'chased' 时)" Q["Query (来自 'chased')<br>我想知道谁在追,追谁?"] K_T["Key (来自 'The')<br>我是个冠词"] K_C["Key (来自 'cat')<br>我是个动物,是主语"] K_CH["Key (来自 'chased')<br>我是个动作"] K_M["Key (来自 'mouse')<br>我是个动物,是宾语"] V_T["Value (The 的信息)"] V_C["Value (cat 的信息)"] V_CH["Value (chased 的信息)"] V_M["Value (mouse 的信息)"] end Q -- 计算相似度 --> K_T Q -- 计算相似度 --> K_C Q -- 计算相似度 --> K_CH Q -- 计算相似度 --> K_M K_T -- "得分: 0.05" --> S[Softmax<br>计算权重] K_C -- "得分: 0.8" --> S K_CH -- "得分: 0.1" --> S K_M -- "得分: 0.9" --> S S -- "权重: 0.02" --> V_T S -- "权重: 0.4" --> V_C S -- "权重: 0.08" --> V_CH S -- "权重: 0.5" --> V_M V_T -- 加权求和 --> O V_C -- 加权求和 --> O V_CH -- 加权求和 --> O V_M -- 加权求和 --> O O["输出 (Output)<br>一个富含'cat'和'mouse'信息的<br>新'chased'表示"] style Q fill:#a2d2ff,stroke:#333,stroke-width:2px style O fill:#bde0fe,stroke:#333,stroke-width:2px
360
- [[啥是稀疏注意力”(Sparse Attention)]]
- 我们用了那么大的精力,终于让机器学会: “Attention is all you need.” 与此同时,人类却正在失去注意力