嵌入是密集的向量,在连续空间中代表词元,捕捉其语义和句法属性。它们通常被随机初始化,或使用像 GloVe 这样的预训练模型进行初始化,然后在训练过程中进行微调。例如,“狗”的嵌入可能会在与宠物相关的任务中不断演变,以反映其上下文,从而提高模型的准确性。
好的,我们来从第一性原理的角度,深入浅出地剖析一下“嵌入(Embeddings)”这个概念,以及它们在大型语言模型(LLM)中是如何被“点燃”的。
核心剖析:什么是嵌入(Embeddings)?
从本质上讲,嵌入(Embeddings)是一种将离散的、高维的、非连续的“符号”转化为低维的、连续的、有意义的“向量”的技术。
听起来很抽象?我们来一步步拆解:
-
“符号” (The Symbol): 在语言模型的世界里,最基本的“符号”就是单词(或字、token)。想象一下人类的语言,比如“猫”、“狗”、“国王”、“女王”。这些词本身只是一个个独立的符号,计算机无法直接理解它们之间的关系。在计算机看来,“猫”和“狗”的差别,就像“苹果”和“橘子”的差别一样,只是两个不同的字符串。
-
“高维、离散” (High-Dimensional, Discrete): 如果我们想让计算机处理这些词,最简单粗暴的方法是“独热编码”(One-hot Encoding)。假设我们的词典里有10000个词,“猫”可能就是
[1, 0, 0, ..., 0],“狗”就是[0, 1, 0, ..., 0]。每个向量的维度都是10000,而且向量之间是“正交”的(相互垂直),这意味着从数学上讲,它们之间没有任何关系。这种表示方式是:- 高维的 (High-dimensional): 维度等于词典大小,非常巨大。
- 离散的/稀疏的 (Discrete/Sparse): 绝大部分元素都是0。
- 无意义的 (Meaningless): 无法捕捉词与词之间的相似性、关联性等语义信息。
-
“转化” (The Transformation): “嵌入”就是解决这个问题的魔法。它将每一个单词“嵌入”到一个相对低维的连续向量空间中。这个过程就像是给每个单词分配一个多维度的坐标。
-
“低维、连续、有意义” (Low-Dimensional, Continuous, Meaningful): 转化后的向量(嵌入向量)具有以下特点:
- 低维 (Low-dimensional): 维度不再是成千上万,而是几百到几千(例如300维、768维、4096维)。这大大提高了计算效率。
- 连续 (Continuous): 向量的每个维度都是一个浮点数,不再是0或1。这使得向量可以在空间中平滑移动。
- 有意义 (Meaningful): 这是最关键的一点。在这个向量空间中,语义上相似的词,其对应的向量在空间中的距离也更近。
隐喻解析:图书馆里的“语义地图”
想象一下,你走进一个巨大的图书馆,里面有成千上万本书(单词)。
-
传统方法(独热编码): 图书管理员按照书名的首字母A-Z来排列。书与书之间除了字母顺序外,没有任何内容上的关联。《算法导论》和《爱丽丝梦游仙境》会挨在一起,但它们的内容风马牛不相及。你无法通过位置找到内容相似的书。
-
嵌入方法(Embeddings): 现在,一位天才图书管理员发明了一种新的图书排列方法。他阅读了每一本书,并根据书的核心内容给每本书分配了一个在图书馆三维空间中的精确坐标(x, y, z)。
- 坐标轴的意义: x轴可能代表“虚构程度”,y轴代表“科技含量”,z轴代表“历史相关性”等等(实际上嵌入的维度没有这么明确的定义,但可以这么理解)。
- 空间中的位置: 在这个“语义地图”上,《相对论》和《量子力学》这两本书的坐标会非常接近;“国王”和“女王”这两个词的坐标也很近;而“猫”和“狗”会聚集在“宠物/动物”这个区域。
- 向量运算的意义: 更有趣的是,从“国王”的坐标指向“女王”的坐标所形成的向量,可能和从“男人”指向“女人”的向量非常相似!这揭示了词与词之间的复杂关系,比如:
Vector("国王") - Vector("男人") + Vector("女人") ≈ Vector("女王")。
嵌入(Embeddings)就是为语言世界里的每一个“单词”绘制这张“语义地图”的过程。大型语言模型(LLM)的整个知识和推理能力,都建立在这张地图的精度和复杂性之上。 (leads to:: LLM 与传统统计语言模型有何不同?)
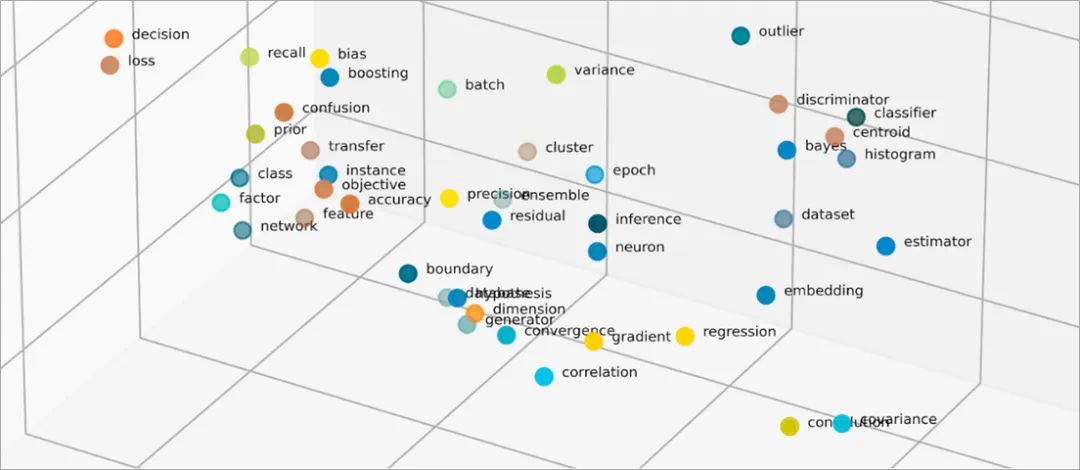
可视化洞察:
想象一个三维空间:
- 点 (Points): 空间中的每一个点,都代表一个单词的嵌入向量。
- 簇 (Clusters): 颜色、动物、国家等概念会各自形成“簇群”。
- 向量 (Vectors): 从一个点指向另一个点的箭头(向量)可以表示它们之间的关系,比如“国家”到“首都”的关系(“法国”→“巴黎”的向量,会和“日本”→“东京”的向量方向和长度相似)。
这张图形象地展示了嵌入空间。相似的概念聚集在一起,并且它们之间的关系可以通过向量来表示。
LLM 中的初始化:嵌入向量的第一束光
现在我们知道了嵌入是什么,那么在训练一个全新的、空空如也的LLM时,这些单词的初始“坐标”是如何设定的呢?这就像是问,在那位天才图书管理员开始摆放书籍之前,他是怎么决定第一本书放在哪里的?
主要有两种方法:
1. 随机初始化 (Random Initialization)
这是最直接、最常见的方法。
-
过程: 在训练开始时,LLM会创建一个巨大的“嵌入矩阵”(Embedding Matrix)。这个矩阵的行数是词典的大小(例如50000个token),列数是预设的嵌入维度(例如4096维)。然后,用一些随机数来填充这个矩阵的每一个位置。通常,这些随机数取自一个特定的概率分布,比如均值为0、方差很小的高斯分布(正态分布)。
-
隐喻: 就像图书管理员闭着眼睛,把图书馆里的每一本书随机扔到书架的某个位置上。初始状态下,整个图书馆是完全混乱的,《相对论》可能被扔在儿童读物区。
-
后续: LLM在训练过程中,会阅读海量的文本数据。每当它预测下一个词出错时,它就会通过反向传播算法(Backpropagation)微调这些随机初始化的嵌入向量。就像图书管理员不断地根据读者反馈(“这两本书内容很像,应该放一起”)来调整书籍的位置。 经过亿万次的调整,这张“语义地图”会从完全的混乱变得井然有序,语义相似的词会慢慢“漂移”到相近的位置。几乎所有现代的LLM(如GPT系列)都采用这种从头开始学习嵌入的方式。
2. 预训练嵌入 (Pre-trained Embeddings)
在LLM变得如此庞大之前,研究人员会使用一些更轻量级的模型(如Word2Vec, GloVe)在大型语料库上专门训练词嵌入。
-
过程: 与其随机初始化,不如直接拿这些已经训练好的、包含了基础语义信息的嵌入向量来作为初始值。
-
隐喻: 这就像是图书馆在开业前,直接雇佣了一批已经有基础图书分类经验的管理员(Word2Vec, GloVe)。他们虽然不是天才,但至少能把科技书、文学书、历史书大致分在不同的区域。这提供了一个比完全随机好得多的“起点”。
-
在LLM中的应用: 在早期的NLP模型中,这种方法非常流行,因为它可以加速模型收敛,并且在数据量不那么大的任务上表现更好。但是,对于现代的、拥有海量参数和训练数据的LLM来说,这种方法的优势就不那么明显了。因为LLM自己有足够强大的能力,可以从零开始,根据自身庞大的模型结构和海量的训练数据,学习到比Word2Vec等方法更深刻、更契合自身需求的嵌入表示。因此,现代LLM倾向于随机初始化,让嵌入层作为整个模型的一部分,共同进行端到端的训练。
总结
总而言之,嵌入是将语言符号化的关键一步,它将离散的单词变成了在多维空间中具有意义的坐标点。而在LLM的创生之初,这些坐标点通常是随机设定的,就像宇宙大爆炸前的奇点,充满了混沌和无限可能。然后,在海量数据的“引力”作用下,这些点在训练过程中不断移动、演化,最终形成了我们所见的、蕴含着复杂知识和语义关系的、结构精妙的“语义宇宙”。
360
contradict:: 把嵌入就认为词元,这是不对的