多头注意力将查询(query)、键(key)和值(value)分割到多个子空间中,允许模型同时关注输入的不同方面。例如,在处理一个句子时,一个“头”可能关注句法,另一个“头”可能关注语义。这提高了模型捕捉复杂模式的能力。
1. 第一性原理分析:从“单一视角”到“多元视角”的进化
问题的起点:单一注意力(Single-Head Attention)的局限性
想象一下,在没有“多头”之前,模型只有一个“注意力头”。这个头在分析句子时,就像一个只有一种工具的工匠。
比如句子:“The animal didn’t cross the street because it was too tired.”(那个动物没有过马路,因为它太累了。)
对于单词 “it”(它),单一的注意力机制需要判断 “it” 指代的是 “animal” 还是 “street”。在这次计算中,它可能成功地将 “it” 和 “animal” 联系起来。
但是,这个句子中还包含其他关系:
- 动作关系:“cross”(穿过)这个动作的主体是 “animal”,宾体是 “street”。
- 因果关系:“because” 连接了两个分句,揭示了因果。
- 修饰关系:“tired”(累了)修饰的是 “it”(也就是 “animal”)。
一个单一的注意力“头”,在一次计算中,很难同时捕捉到所有这些不同类型的关系。它可能会优先学习最重要的关系(比如指代关系),而忽略其他次要但同样有用的信息。这就好比让一个人同时听好几个人说话,很容易顾此失彼。
“多头”的解决方案:分而治之,再统合起来
多头注意力(Multi-Head Attention)的核心思想是:不要只用一个工匠,而是请来一个各有所长的专家团队。
-
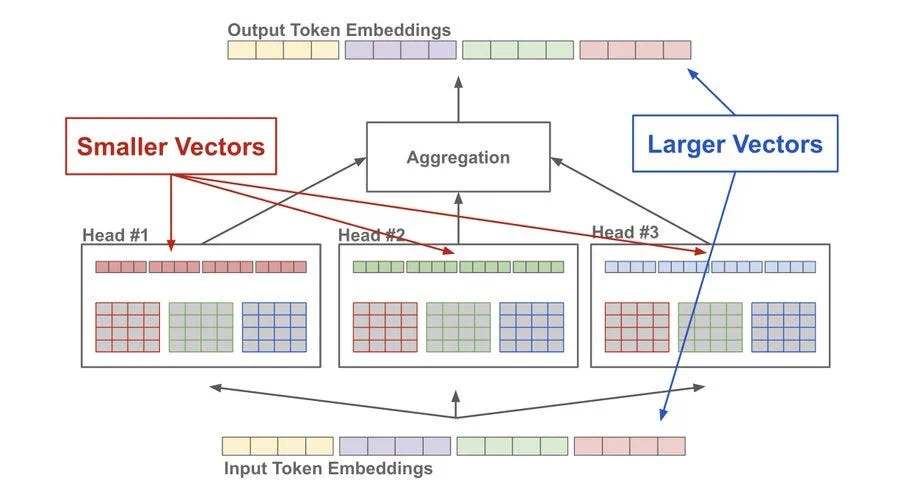
分割(Splitting into Subspaces):这并不是把句子分割成几段。而是把代表每个单词的向量信息(Query, Key, Value)“劈”成好几份(比如8份或12份)。想象一个本来维度是512的向量,现在被分成了8个维度为64的小向量。每一份都交给一个独立的“头”去处理。
-
专业化(Simultaneous Focus on Different Aspects):由于每个头拿到的信息更“小”、更“专注”,它们在训练过程中会逐渐学会捕捉不同类型的关系。就像你给了8个专家不同的初始工具和任务,他们会各自发展出自己的专长:
- 头1号 可能变成了“指代关系专家”,专门寻找代词(it, they, he)和它们指向的名词(animal, boy)。
- 头2号 可能变成了“句法结构专家”,专门分析主谓宾结构。
- 头3号 可能变成了“同义词/反义词专家”,关注词与词之间的语义关联。
- 头4号 可能只关注相邻词语的关系。
- …等等。
-
整合(Concatenation & Fusion):在所有“专家头”都完成自己的分析后,它们会各自给出一个“报告”(一个输出向量)。系统会将这8份报告拼接起来,然后通过一个最终的“决策层”(一个线性层)进行融合。这样,最终输出的单词表示,就同时包含了来自句法、语义、指代等多个维度的丰富信息。
2. 一个生动的比喻:专家委员会审阅报告
想象你要彻底理解一份极其复杂的法律文件(输入的句子)。
-
单一注意力:你聘请了一位全科律师。他通读了文件,给出了他的总体理解。他很可能抓住了合同的核心条款,但可能会忽略财务责任的精算细节、知识产权的归属问题或劳动法方面的潜在风险。他的理解是单维度的。
-
多头注意力:你成立了一个专家委员会(Multi-Head)。
- 分割:你把法律文件复印了8份,分发给8位专家。
- 专业化:这8位专家背景各不相同:
- 一位是合同法专家(头1,关注权利义务关系)。
- 一位是财务律师(头2,关注数字和金额条款)。
- 一位是知识产权律师(头3,关注专利和版权归属)。
- 一位是诉讼律师(头4,关注争议解决条款)。
- …
- 同时关注:他们同时阅读同一份文件,但每个人都戴着自己专业领域的“眼镜”(独特的Q, K, V权重矩阵),去寻找和关注文件中与自己专业相关的部分。
- 整合:最后,你把这8位专家的分析报告收集起来,订在一起,形成一份最终的、极其详尽、视角全面的综合分析报告(拼接并融合后的最终向量)。
这份综合报告的深度和广度,是那位全科律师远远无法比拟的。这就是多头注意力的力量:通过并行地、多角度地审视信息,获得一个远比单一视角更丰富、更鲁棒的理解。
3. 一幅清晰的画面:彩色的注意力光束
让我们把这个过程可视化。想象句子 “机器人拿起红色的积木,因为它很轻” 漂浮在空间中。
-
输入:句子中的每个词(机器人, 拿起, 红色, 积木, 因为, 它, 很, 轻)都是一个信息点。
-
分解:从每个词语信息点,不是射出一束白光,而是同时射出多束不同颜色的光(比如红、绿、蓝、黄…)。每种颜色的光代表一个“头”。
-
聚焦:现在,神奇的事情发生了。
- 代表“它”的那个点,射出的红色光束(指代关系头)会非常明亮地照在“积木”上。
- 代表“拿起”的点,射出的绿色光束(句法关系头)会同时照亮“机器人”(主语)和“积木”(宾语)。
- 代表“红色”的点,射出的蓝色光束(修饰关系头)会精准地照亮“积木”。
- 也许还有一道黄色光束(位置关系头),把所有相邻的词都微弱地连接起来。
-
整合:当我们要计算“积木”这个词的最终含义时,我们会看到它被多道光束照亮了:来自“拿起”的绿色光(表示它被拿起),来自“红色”的蓝色光(表示它的颜色),以及来自“它”的红色光(表示它被指代)。所有这些射入的光束信息被融合,形成了一个全新的、五彩斑斓的“积木”信息点。
这个新的“积木”不仅知道自己是个积木,它还同时知道了**“我是一个被机器人拿起的、红色的、并且在下文被称为‘它’的那个很轻的东西”**。
总结一下:多头注意力机制,本质上是一种并行化的、多元化的视角综合。它避免了模型在理解复杂信息时陷入“只见树木,不见森林”或“只见森林,不见树木”的困境,让模型既能把握全局的句法结构,又能洞察局部的语义细节,从而极大地增强了对语言复杂模式的捕捉能力。