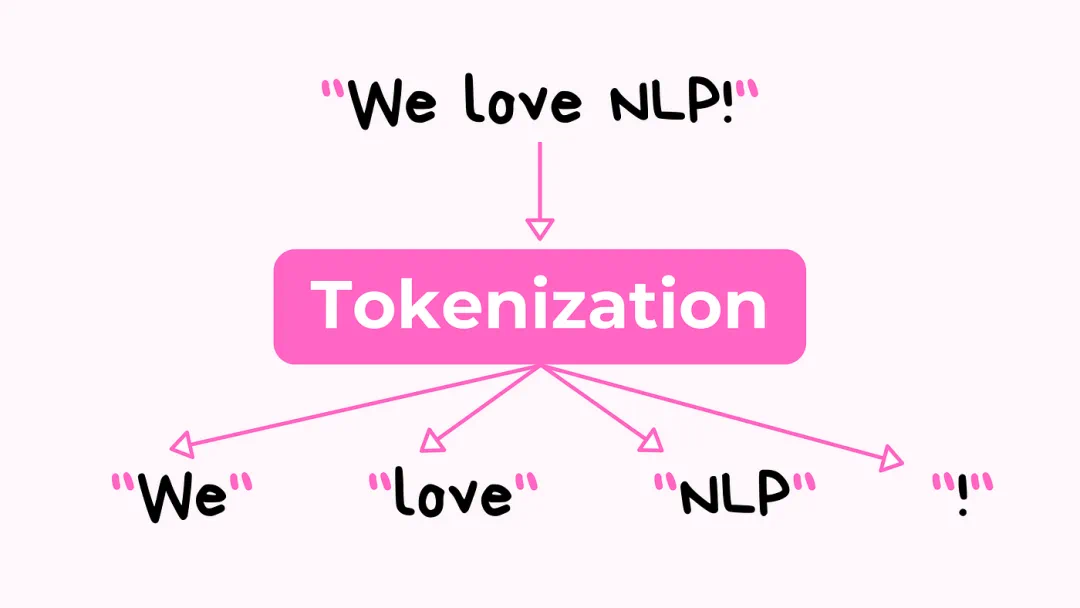
分词(Tokenization)是指将文本分解成更小的单元,即 “词元”(token),例如单词、子词或字符。例如,“artificial” 可能会被分解为 “art”、“ific” 和 “ial”。这个过程至关重要,因为 LLM 处理的是词元的数字表示,而不是原始文本。分词使模型能够处理多种语言、管理罕见或未知词汇,并优化词汇表大小,从而提高计算效率和模型性能。
Readaloud
LLM 并不直接理解“语言”,而是先将句子切分为词元(Tokens),再将每个词元映射为一个数字 ID 或向量,最后由模型处理这些数字来理解上下文与生成内容。